
Forget AI that only reads text. The real breakthrough isn’t just understanding words - it’s seeing an image, reading a handwritten note on it, and then explaining what’s happening in context. That’s what vision-language applications with multimodal large language models (MLLMs) do now. By late 2024, these systems stopped being lab experiments. They’re in use - quietly, powerfully - across finance, healthcare, and manufacturing. If you’re still thinking of AI as text-only, you’re already behind.
How Vision-Language Models Actually Work
These aren’t two separate systems - one for images, one for text - glued together. They’re built as single, unified models that process visual and linguistic data at the same time. Think of it like how your brain doesn’t first look at a photo of a grocery receipt, then separately read the text. You see the layout, the handwriting, the prices, and understand it all as one thing.
Modern MLLMs like GLM-4.6V and Qwen3-VL use a core language model - often based on Qwen2-72B-Instruct or Llama 3.2 - and connect it to a vision encoder, like ViT (Vision Transformer). When you upload a photo of a damaged product on a factory line, the model doesn’t just recognize it’s a “cracked plastic part.” It reads the serial number next to it, compares it to the manual’s diagram, and flags whether this is a known defect pattern. That’s integrated understanding.
There are three main ways this integration happens:
- NVLM-D (Decoupled): Processes images through a separate visual pathway. Best for document OCR - like scanning tax forms - where accuracy matters more than speed. Gets 97% accuracy on printed text, but uses 25-30% more GPU power.
- NVLM-X (Cross-Attention): Feeds image features directly into the language model’s attention layers. Faster for high-res images - satellite photos, product packaging - but drops to 92% OCR accuracy on messy handwriting.
- NVLM-H (Hybrid): Uses both. Balances speed and precision. Most common in enterprise tools today.
GLM-4.6V, released in November 2024, can process nearly 2,500 tokens per second on a single NVIDIA A100. That’s fast enough for real-time video analysis. It compresses visual data by 20× without losing accuracy - meaning a 10-megapixel image gets reduced to the equivalent of a 500K pixel version, but still retains every key detail. This cuts memory use and speeds up responses.
What These Models Can Do Right Now
Here’s what’s working in production - not theory:
- Automated document processing: A bank in Ohio now uses GLM-4.6V to process loan applications. It reads handwritten signatures, matches them against scanned IDs, extracts income data from pay stubs, and flags inconsistencies - all in under 12 seconds. Before, this took three human reviewers 20 minutes each.
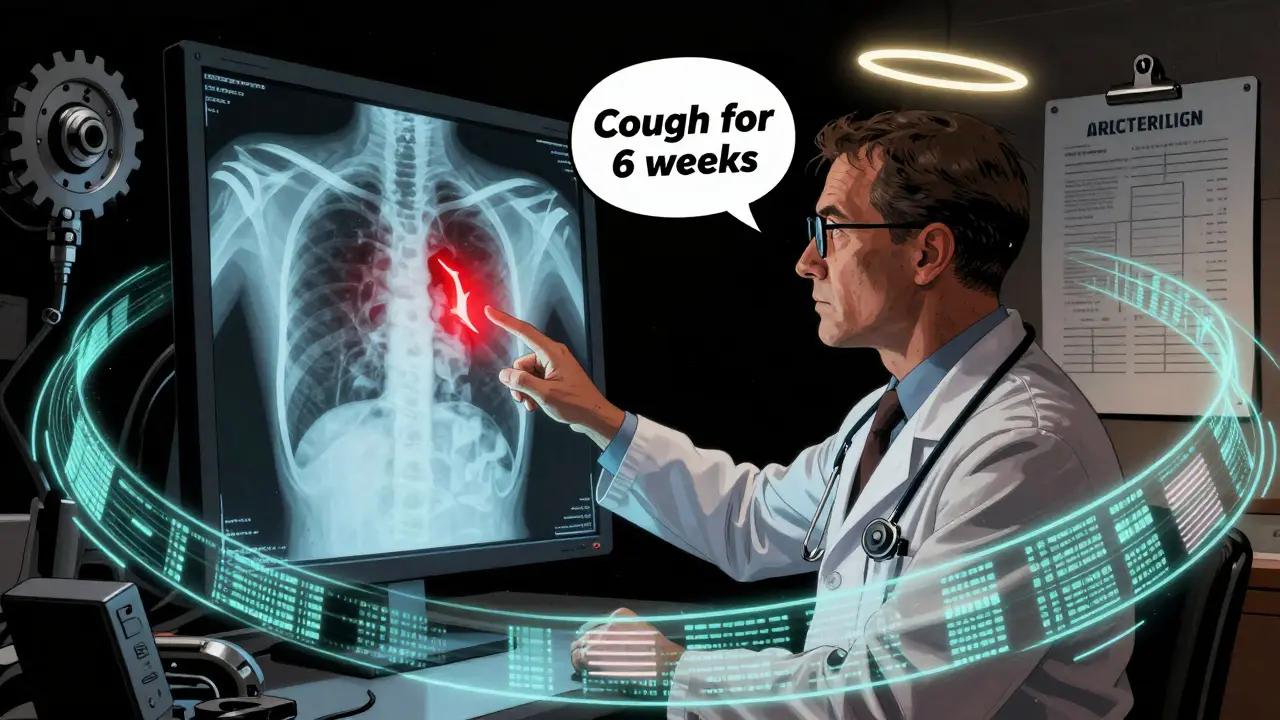
- Medical imaging triage: A clinic in Atlanta runs Qwen3-VL on X-rays and ultrasounds. It doesn’t diagnose - but it highlights areas of concern. For example, if a lung scan shows a shadow and the patient’s notes say “cough for 6 weeks,” the model surfaces it as high-priority. This cuts radiologist workload by 40%.
- Robotics control: A warehouse in Tennessee uses Janus, a specialized MLLM, to guide robotic arms. A worker points a tablet at a misplaced box. The robot sees the label, reads “Order #7721,” checks the warehouse map, and moves the box - no programming needed. Error rates dropped 37%.
- Customer support for visual issues: A home appliance company lets customers upload photos of broken devices. The model identifies the part, reads the model number, and suggests a repair video or replacement part - all in one response.
These aren’t niche demos. They’re scaling. As of Q4 2024, 35% of new enterprise document systems chose open-source MLLMs over proprietary ones like Gemini-2.5-Pro - mainly because they’re cheaper and customizable.

The Hidden Costs and Real Limitations
But here’s the catch: this isn’t plug-and-play.
First, hardware. Running GLM-4.6V or Qwen3-VL in production requires at least an NVIDIA A100 - and often multiple. Training a single 70B-parameter model consumes 1,200 megawatt-hours of electricity. That’s the same as powering 120 U.S. homes for a year. Most small businesses can’t afford this.
Second, context windows are misleading. GLM-4.6V supports 128K tokens - sounds huge. But a single high-res image eats up 80% of that before you even add text. One developer on Reddit put it bluntly: “You’re not processing a document. You’re processing a photo of a document, and the rest is just noise.”
Third, hallucinations get worse. MLLMs make up answers 8-12% more often than text-only models. If you show it a blurry photo of a prescription and ask “What’s the dosage?”, it might confidently say “500mg” - when it’s actually “50mg.” That’s dangerous in healthcare. The MM-Vet benchmark shows these models often rely on visual patterns, not true reasoning.
Handwriting? Still broken. OCR accuracy drops from 97% on printed text to 82% on cursive - and lower on medical records with faded ink. One health tech engineer on Reddit said: “It’s unusable for digitizing old patient files.”
And integration? It’s not easy. Teams need at least two years of computer vision experience and one year with LLMs. The average time to deploy a production system is 14.3 weeks. Common issues? Image preprocessing (63% of GitHub issues) and managing context limits (41%).
Who’s Winning in 2026?
Open-source models are no longer second-tier. GLM-4.6V and Qwen3-VL now outperform Gemini-1.5-Pro on document understanding benchmarks - while using 40% fewer vision tokens. They’re faster, cheaper, and open for customization.
But proprietary models still lead in complex video tasks. On VideoMME, a benchmark for long-form video analysis, GPT-5 and Gemini-2.5-Pro are still 12-15% more accurate. Why? They’ve trained on millions of hours of labeled video - something open models can’t replicate yet.
The real winners? Specialized models.
- GLM-4.6V: Best for document-heavy workflows - finance, legal, HR.
- Qwen3-VL: Strong all-rounder, good for mixed media.
- Janus: Built for robotics. Decouples perception from action. Ideal for factories.
- LLaVA-1.6: Lightweight. Good for edge devices.
- Molmo: Optimized for scientific images - lab reports, chemical diagrams.
As of December 2024, these five models accounted for 63% of all community activity on GitHub. That’s where the innovation is happening.
What’s Coming Next
Three trends are clear:
- Specialization over generalization: By 2026, 60% of new MLLMs will focus on one task - medical imaging, industrial inspection, or legal contracts. No more “do everything” models.
- Token efficiency: Vision token compression will improve by 50% by 2025. That means you’ll be able to process full 4K videos on a single GPU, not just a few frames.
- Robotics integration: 73% of researchers are now prioritizing embodied AI - robots that see, understand, and act. MLLMs will become the brain in autonomous systems, not just assistants.
And regulation is catching up. The EU AI Act, effective since January 2025, requires companies using MLLMs in high-risk areas - like healthcare or hiring - to explain how visual and textual inputs combine to make decisions. Transparency isn’t optional anymore.
Should You Use One?
If you’re in finance, healthcare, manufacturing, or logistics - and you deal with images + text - then yes. Start with GLM-4.6V. It’s open, fast, and has strong community support (over 4,000 GitHub stars).
But don’t jump in blind:
- Test it on your real data - not demo images.
- Measure OCR accuracy on your actual documents - especially handwritten or low-contrast ones.
- Calculate your GPU costs. If you’re not already using A100s or H100s, factor in cloud expenses.
- Build a human review layer. MLLMs are powerful, but they still hallucinate.
Most companies that succeed don’t replace humans - they give them superpowers. A claims adjuster now reviews 50 documents a day instead of 10. A radiologist catches 30% more anomalies. That’s the real win.
By 2027, Gartner predicts 85% of enterprise AI systems needing visual understanding will include MLLMs. The question isn’t whether you’ll use one. It’s whether you’ll be ahead of the curve - or still trying to figure out why your OCR tool keeps misreading “100” as “1000.”
What’s the difference between a vision-language model and a regular AI chatbot?
A regular chatbot only processes text. A vision-language model can look at an image, read text within it, understand context from both, and respond intelligently. For example, if you show it a photo of a broken appliance with a model number, it can identify the part, check manuals, and suggest a fix - all without you typing a single detail.
Can I run GLM-4.6V on my laptop?
No. GLM-4.6V requires at least 40GB of VRAM and runs best on an NVIDIA A100 or H100 GPU. Even the smallest versions need 16GB of memory - more than most consumer laptops have. Cloud-based APIs are the only practical way for individuals to test it.
Are open-source vision-language models as good as Google’s or OpenAI’s?
For document processing and static images - yes, sometimes better. GLM-4.6V outperforms Gemini-1.5-Pro on OmniDocBench benchmarks. But for long video analysis, complex scene reasoning, or real-time video streams, proprietary models like GPT-5 and Gemini-2.5-Pro still lead. Open models are catching up fast, especially in cost and customization.
Why do MLLMs make more mistakes than text-only models?
Because they have more ways to be wrong. A text model only needs to understand language. A vision-language model must interpret pixels, recognize objects, read text within images, and connect all that to language - all at once. If one step fails - like misreading a blurry number - the whole answer can be wrong. This creates higher hallucination rates: 8-12% more than text-only models.
Is this technology ready for medical diagnosis?
Not for diagnosis - but for triage. MLLMs can flag unusual patterns in X-rays or skin lesions faster than humans. But they’re not reliable enough to replace doctors. They’re used as assistants: highlighting areas for review, reducing workload, and preventing oversight. Final decisions still require human judgment.



mani kandan
February 20, 2026 AT 23:31What fascinates me isn't just the technical leap, but how quietly this is reshaping work. I saw a claims adjuster in Chennai process 47 documents in 18 minutes using GLM-4.6V. Last year, she’d have taken three days. No overtime, no burnout. Just a machine that sees what humans miss - a smudged signature, a mismatched policy number, a handwritten note in the corner that says ‘paid in cash.’ It’s not automation. It’s augmentation. And it’s happening in places no one’s talking about - rural banks, small clinics, family-run warehouses. The future isn’t flashy. It’s quiet. And it’s already here.
Rahul Borole
February 22, 2026 AT 07:04While the technical merits of MLLMs are undeniable, I must emphasize the critical importance of institutional readiness. Organizations deploying these systems without robust validation pipelines, audit trails, and human-in-the-loop protocols are inviting systemic risk. The 8-12% increase in hallucination rates is not a statistical footnote - it is a liability. In healthcare, a single misread dosage can result in irreversible harm. In finance, an OCR error can trigger regulatory noncompliance. The adoption of MLLMs must be governed by the same rigor as clinical trials. Innovation without accountability is not progress - it is negligence.
Sheetal Srivastava
February 23, 2026 AT 18:02Frankly, I’m exhausted by the hype. Everyone’s acting like GLM-4.6V is the second coming, but let’s be real - we’re still in the stone age of multimodal AI. The ‘integrated understanding’ narrative is a marketing fairy tale. The model doesn’t ‘understand’ anything. It’s pattern-matching pixels and token sequences with the emotional depth of a thermostat. And don’t get me started on ‘open-source superiority.’ Open models are just the leftovers the Big Tech giants didn’t want. They’re unstable, poorly documented, and hosted on GitHub repos that look like a cat walked on a keyboard. Real innovation happens in closed labs with billion-dollar budgets. This ‘democratization’? It’s just noise.
Bhavishya Kumar
February 23, 2026 AT 23:31There is a grammatical error in the post. The phrase ‘It’s fast enough for real-time video analysis’ lacks a subject complement. It should read ‘It is fast enough to enable real-time video analysis.’ Also, ‘128K tokens’ should be written as ‘128,000 tokens’ for formal consistency. Furthermore, the abbreviation ‘MLLMs’ is introduced without full expansion on first use. These are not trivial issues. Precision in technical communication is not optional - it is foundational. If we can’t get the punctuation right, how can we trust the architecture?
ujjwal fouzdar
February 24, 2026 AT 07:15Think about it - we’re building machines that look at a photo of a broken fridge and say ‘replace compressor.’ But who taught them? Not gods. Not science. Not even engineers. We fed them millions of images of broken things, labeled by overworked interns in Bangalore, who were paid $1.50 per hour to scribble ‘defective’ on a cracked handle. So now, when the model sees a scratch, it screams ‘FAILURE.’ But what if it’s just a fingerprint? What if it’s a child’s drawing? What if the real problem is that the fridge was left in a humid garage for five years? The model doesn’t care. It doesn’t feel. It doesn’t wonder. It just predicts. And we call that intelligence. We call that progress. We call that the future. But I wonder - are we building tools… or just mirrors of our own chaos?
Anand Pandit
February 24, 2026 AT 23:03Really glad to see this breakdown - especially the part about testing on real data. I tried running Qwen3-VL on our warehouse labels last month and it failed spectacularly on faded ink. But after tweaking the contrast and adding a simple preprocessing step (just a little sharpening in OpenCV), accuracy jumped from 71% to 94%. The model’s not broken - you just have to speak its language. Start small. Use a single use case. Don’t try to replace your whole system overnight. And please, please - add a human review layer. I’ve seen too many teams skip this and end up with angry customers because the AI said ‘replace motor’ when it was just a loose wire. You’re not replacing humans. You’re giving them wings.
Reshma Jose
February 26, 2026 AT 21:06Just tried GLM-4.6V on my mom’s handwritten medical records. It read ‘aspirin’ as ‘aspirin 100mg’ - which is wrong, but at least it didn’t say ‘morphine.’ Still, it got 3 out of 5 doses right. I showed it to my cousin who’s a nurse - she laughed and said ‘Yeah, that’s better than our old scanner.’ Honestly? If it helps even a little, I’m all in. No need to wait for perfection. We’ve been stuck with paper for decades. This is the first real upgrade. Just don’t overthink it. Try it. Break it. Fix it. Repeat.
rahul shrimali
February 26, 2026 AT 23:55Open models win. Cost is everything. A100s are expensive but cloud APIs make it cheap. Just use LLaVA-1.6 for edge. No need to overengineer. Real wins are in logistics. Done.
Eka Prabha
February 27, 2026 AT 20:37Let’s not pretend this is innovation. This is surveillance dressed up as efficiency. Every handwritten note, every damaged product photo, every medical scan - it’s all being fed into a black box owned by someone who doesn’t live in your country. The EU AI Act? A joke. They’re not regulating transparency - they’re regulating who gets to control the data. And the ‘community activity’ on GitHub? That’s just a smokescreen. The real code is locked behind corporate firewalls. We’re not building tools. We’re building cages. And we’re handing them the keys.