
You’ve seen the headlines. The biggest language models are getting smarter, faster, and more capable every month. But there’s a catch: running them costs a fortune. If you want to deploy an AI assistant on your website, in your mobile app, or even on a local server, paying for massive cloud inference every time a user sends a message isn’t just expensive-it’s often impossible. This is where knowledge distillation comes in.
Think of it like this: you hire a world-class expert (the "teacher") to train a junior employee (the "student"). The junior doesn’t need to know everything the expert knows, but they learn the expert’s way of thinking, their decision-making process, and their best practices. In AI terms, we take a huge, powerful model like GPT-4 or LLaMA-3-70B and use it to teach a much smaller, cheaper model how to behave. The result? A lightweight model that performs surprisingly well without the heavy price tag.
How Knowledge Distillation Actually Works
At its core, knowledge distillation is about transferring knowledge from a large Teacher Model to a smaller Student Model. Traditional machine learning trains models to predict the single correct answer-the "hard label." For example, if asked "What is the capital of France?" the model learns that "Paris" is right and "London" is wrong.
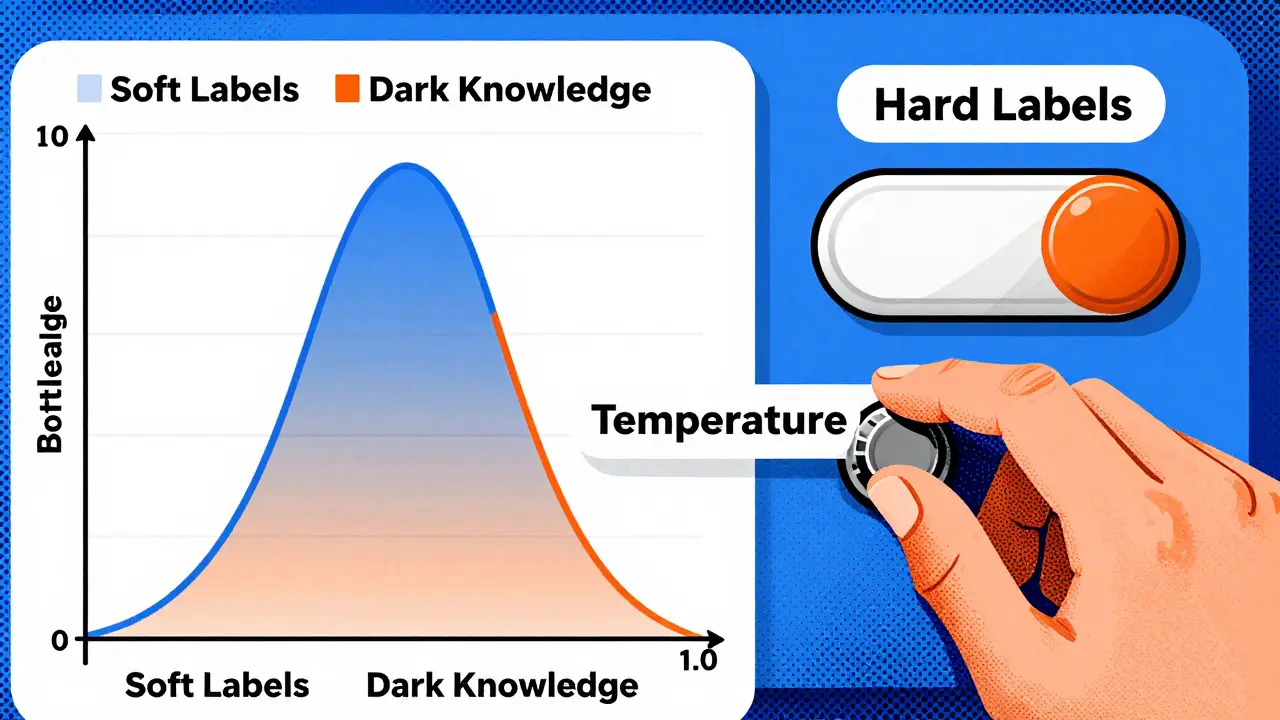
Distillation changes the game. Instead of just looking at the right answer, the student looks at the teacher’s entire probability distribution-the "soft labels." When the teacher sees the question, it might assign a 90% probability to "Paris," a 5% chance to "Lyon," and tiny probabilities to other cities. These small probabilities contain hidden information, or what researchers call "dark knowledge." They tell the student that Lyon is geographically related to France, while London is not. By mimicking these nuanced probabilities, the student learns context and relationships, not just facts.
This technique was popularized in 2015 by Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. While it started with simple neural networks, it has become essential for Large Language Models (LLMs) since 2022. As models grew beyond 100 billion parameters, direct deployment became too costly for most organizations. Distillation allows companies to compress these giants into manageable sizes without losing critical performance.
The Core Components of the Distillation Process
To make distillation work, you need three main ingredients: the teacher, the student, and a loss function that guides the learning.
- The Teacher: This is your high-performance, often proprietary or open-source large model (e.g., GPT-4, LLaMA-3-70B). It provides the ground truth and the soft probability distributions.
- The Student: This is the smaller model you are training (e.g., a 3B or 7B parameter model). It could be a pruned version of the teacher or a completely different architecture designed for speed.
- The Loss Function: This is the mathematical rule that tells the student how far off it is from the teacher. Most systems use a combination of Kullback-Leibler (KL) divergence to match the teacher’s probability distribution and standard cross-entropy to ensure the student still predicts the correct hard labels.
A key technical detail here is the "temperature" parameter. By raising the temperature during the teacher’s output generation, we soften the probability distribution. This makes the differences between likely and unlikely tokens more pronounced, helping the student learn the relative rankings of options rather than just the top choice.
Types of Knowledge You Can Transfer
It’s not just about copying text. Modern distillation transfers several layers of intelligence:
- Logit-Level Knowledge: The student matches the teacher’s token-level probability distribution at each step. This is the most common form and captures the "uncertainty" and nuance of the teacher’s reasoning.
- Sequence-Level Knowledge: Here, the teacher generates full responses (like summaries or code snippets), and the student is trained to reproduce those exact sequences. This is often called "data distillation" or synthetic data augmentation.
- Preference-Level Knowledge: If the teacher has been aligned with human feedback (RLHF), the student can learn those preferences. This helps transfer safety guidelines and tone, ensuring the smaller model doesn’t just sound smart but also behaves appropriately.
- Intermediate Representation Knowledge: Advanced techniques involve matching the internal activations or attention patterns of the teacher. This forces the student to process information in a similar way internally, not just externally.
Practical Implementation: From Theory to Code
Let’s look at a concrete example using NVIDIA’s NeMo framework, which is widely used for industrial-scale distillation. Imagine you have a Meta-Llama-3.1-8B model and want to create a faster 4B version.
First, you perform pruning. You might drop half the transformer layers (depth pruning) or reduce the hidden size (width pruning). This creates a structurally smaller student model. However, pruning alone kills performance. That’s where distillation saves the day.
In the NeMo pipeline, you would:
- Load the 8B teacher model.
- Prepare your dataset using the teacher’s tokenizer.
- Run the teacher to generate logits (probability scores) for the dataset.
- Train the 4B student to minimize the difference between its own logits and the teacher’s.
This process typically runs on multiple GPUs. For instance, a setup might use 8 GPUs per node with a global batch size of 128. The goal is to recover the performance lost during pruning. By the end, your 4B model might perform within a few percentage points of the 8B model on benchmarks like MMLU, but it will run twice as fast and use half the memory.
Cost vs. Benefit: Is It Worth It?
Distillation isn’t free. The biggest hurdle is computational cost. "Proper" distillation requires a forward pass through the teacher model for every single token in your training data. Since the teacher is huge, this doubles your training compute compared to standard fine-tuning.
However, the trade-off is usually worth it. Consider the inference costs. Running a 70B model might cost $0.01 per 1,000 tokens. A distilled 7B model might cost $0.001. Over millions of queries, the savings are massive. Plus, latency drops significantly. A distilled model can often respond in under 200 milliseconds on a single GPU, whereas the teacher might take seconds.
There are ways to cut costs. Google’s Gemma models, for example, use "sampled soft labels." Instead of calculating probabilities for all 128,000 tokens in the vocabulary, they sample only the top 256 most likely tokens. This reduces memory traffic and computation drastically while still transferring most of the useful knowledge.
| Technique | Primary Goal | Impact on Accuracy | Best Use Case |
|---|---|---|---|
| Quantization | Reduce precision (e.g., FP16 to INT4) | Minimal loss if done carefully | Memory-constrained devices, edge AI |
| Pruning | Remove redundant weights/layers | Moderate loss without recovery | Speeding up inference on existing hardware |
| Knowledge Distillation | Transfer behavior to smaller architecture | Low loss with proper tuning | Creating efficient standalone models |
| Combined Approach | Distill + Prune + Quantize | Optimized balance | Production-grade enterprise deployment |

Limitations and Pitfalls to Avoid
Don’t expect magic. A student model cannot fundamentally exceed the capabilities of its teacher. If the teacher hallucinates or holds biases, the student will likely inherit them. In fact, distillation can sometimes amplify biases if the teacher’s confidence in incorrect answers is high.
Another risk is overfitting. If you rely too heavily on the teacher’s soft labels and ignore ground-truth data, the student might mimic the teacher’s errors rather than learning the underlying task. A good rule of thumb is to balance the loss function: keep a significant weight on the standard cross-entropy loss (ground truth) alongside the KL divergence (teacher imitation).
Also, consider the "capacity gap." If you try to squeeze a 70B model’s knowledge into a 1B parameter student, you’ll hit a wall. The student simply doesn’t have enough neurons to store the complex patterns. Aim for a reduction factor of 2x to 10x for best results.
Future Trends: Flipping the Script
Research is evolving rapidly. One exciting development is "flipped knowledge distillation," where small, specialized models teach large general-purpose models. For example, a tiny model trained specifically on legal jargon might teach a giant LLM how to handle contract analysis better. This suggests that distillation is becoming less about pure compression and more about merging diverse expertise across models of all sizes.
As we move into 2026, expect to see more automated distillation pipelines. Tools will increasingly allow you to specify your target latency and budget, and the system will automatically select the right teacher, prune the student, and tune the hyperparameters. Knowledge distillation is no longer just a research curiosity; it’s the backbone of practical, scalable AI.
What is the difference between quantization and knowledge distillation?
Quantization reduces the numerical precision of the model's weights (e.g., from 16-bit floats to 4-bit integers) to save memory and speed up math operations. Knowledge distillation trains a smaller, entirely new model to mimic the behavior of a larger one. They are often used together: you distill a small model and then quantize it for maximum efficiency.
Can I use knowledge distillation with open-source models?
Yes, absolutely. You can use a large open-source model like LLaMA-3-70B as the teacher and train a smaller model like Mistral-7B or a custom 3B model as the student. Many developers use this approach to create specialized models for specific industries without relying on proprietary APIs.
How much data do I need for distillation?
You don't need billions of tokens. Because the teacher provides rich "soft labels," distillation is highly data-efficient. High-quality datasets with hundreds of thousands of examples are often sufficient to achieve strong performance, especially when combined with instruction tuning.
Is knowledge distillation computationally expensive?
Training is more expensive than standard fine-tuning because you must run the large teacher model on every training example. However, this is a one-time cost. The resulting student model is much cheaper to run in production, leading to significant long-term savings in inference costs.
What is the role of the temperature parameter?
The temperature parameter smooths the probability distribution output by the teacher. A higher temperature makes the distribution softer, revealing more information about the relative likelihood of incorrect tokens. This helps the student learn subtle relationships and nuances that a hard label would hide.


