
You spent months training your large language model. It writes code, drafts emails, and generates images with stunning realism. But then a user complains that the model consistently portrays doctors as men and nurses as women. Or worse, it denies loan applications from specific neighborhoods at a statistically higher rate than others. This isn't just a PR headache; it's a systemic failure of fairness testing, a critical process designed to identify and mitigate biases in generative AI systems that create text, images, audio, and video.
Unlike traditional machine learning models that output simple classifications or scores, generative AI is stochastic. The same prompt can yield different results depending on sampling variability. This randomness makes measuring fairness incredibly difficult. If you run the same test twice, do you get the same biased outcome? How do you quantify "unfairness" when the output is creative text rather than a binary decision?
The stakes have never been higher. With regulations like the EU AI Act and New York City’s Local Law 144 taking effect, organizations can no longer treat bias as an afterthought. In 2023, a major bank faced a $12 million settlement because its generative AI loan assistant disproportionately denied applications from majority-Black neighborhoods. This article breaks down how to move beyond vague promises of "ethical AI" into concrete metrics, rigorous audits, and actionable remediation plans.
Why Traditional Metrics Fail Generative AI
If you’ve worked with traditional machine learning, you’re likely familiar with accuracy, precision, and recall. These metrics work well when the model outputs a single, deterministic label. But generative AI doesn’t work that way. It generates sequences of tokens based on probability distributions.
This creates a fundamental challenge for fairness evaluation. A model might generate a perfectly neutral response 90% of the time, but in that remaining 10%, it produces highly stereotypical content. Traditional aggregate metrics mask these tail risks. As Google’s Machine Learning Crash Course notes, metrics calculated against an entire validation set often fail to reveal subgroup disparities.
To address this, we need specialized frameworks. The National Institute of Standards and Technology (NIST) positions fairness testing as one of four essential pillars of AI risk management, alongside accuracy, safety, and security. However, implementing this requires moving beyond simple statistical parity to more nuanced measures that account for the complexity of generated content.
| Metric Type | Focus | Example Measure | Limitation |
|---|---|---|---|
| Group Fairness | Equal distribution of outcomes across demographic groups | Demographic Parity (e.g., 78% positive responses for Group A vs. 79% for Group B) | May ignore individual context; hard to apply to open-ended text |
| Individual Fairness | Similar inputs produce similar outputs regardless of identity | Cosine similarity > 0.85 on embedding spaces for identical prompts with different names | Requires high-quality embeddings; sensitive to minor input variations |
| Disparate Impact | Ratio of favorable outcomes between protected and reference groups | Ratio below 0.8 triggers compliance concerns under NYC Local Law 144 | Legal threshold may not capture subtle cultural harms |
| Intersectional Analysis | Compounding biases across multiple identities (e.g., race + gender) | Error rates for Black female patients vs. white male patients | Data sparsity; requires large, diverse datasets |
Key Metrics for Measuring Bias
To effectively test your model, you need specific, measurable indicators. Here are the core metrics used in modern fairness audits:
- Demographic Parity: This metric ensures that the probability of a favorable output is equal across all demographic groups. For example, if your hiring chatbot recommends candidates, it should recommend qualified candidates from Group A and Group B at roughly the same rate. A significant deviation (e.g., 78% vs. 60%) signals potential bias.
- Equalized Odds: This goes a step further by requiring similar true positive and false positive rates across groups. If your model identifies fraudulent transactions, it shouldn’t falsely flag minority users at a higher rate than majority users while missing actual fraud equally.
- Disparate Impact Ratio: Adapted from U.S. employment law, this ratio compares the selection rate of a protected group to the reference group. A ratio below 0.8 is generally considered evidence of discrimination. In the context of generative AI, this might mean comparing how often positive adjectives are associated with different ethnic names in generated descriptions.
- Stereotype Association Scores: Using datasets like StereoSet, you can measure how strongly your model associates certain traits with specific identities. For instance, does the model link "nurse" with "she" significantly more often than "doctor" with "he"?
It’s crucial to understand that no single metric tells the whole story. Dr. Timnit Gebru, founder of the Distributed AI Research Institute, emphasizes that fairness testing must address both representation harms (who is shown?) and allocation harms (who gets resources?). You need a combination of these metrics to get a holistic view.

Conducting Comprehensive AI Audits
Metrics are useless without data. An effective audit requires specialized datasets and methodologies designed to probe the model’s weaknesses. Here’s how leading organizations structure their audits:
1. Use Specialized Bias Detection Datasets
General-purpose benchmarks won’t cut it. You need datasets explicitly designed to test for bias. Two prominent examples include:
- StereoSet (v3.0): Released in June 2023, this dataset contains 1,880 prompts spanning gender, race, and religion categories. It tests whether the model reinforces stereotypes or challenges them.
- HolisticBias: This framework evaluates the portrayal of 14 identity groups across over 5,000 prompts. It achieves 92% inter-annotator agreement, making it a reliable tool for consistent measurement.
2. Perform Intersectional Analysis
Most early fairness tests looked at single dimensions-either race or gender. This misses the reality of human experience. IBM’s AI Fairness 360 toolkit allows for intersectional auditing across eight demographic dimensions simultaneously. A 2024 case study revealed that a healthcare chatbot had only a 17% error rate difference when analyzing gender alone, but a staggering 41% higher error rate for Black female patients compared to white male patients when both factors were considered together.
3. Engage in Participatory Auditing
Internal teams often suffer from blind spots. Meta’s Responsible AI Community program demonstrated the value of external perspectives by paying 200+ diverse contributors $75/hour to identify biases. This approach uncovered 37% more harmful outputs than internal testing alone. Consider partnering with community organizations or academic researchers who represent the populations most affected by your AI.
Remediation Plans: Fixing the Problems
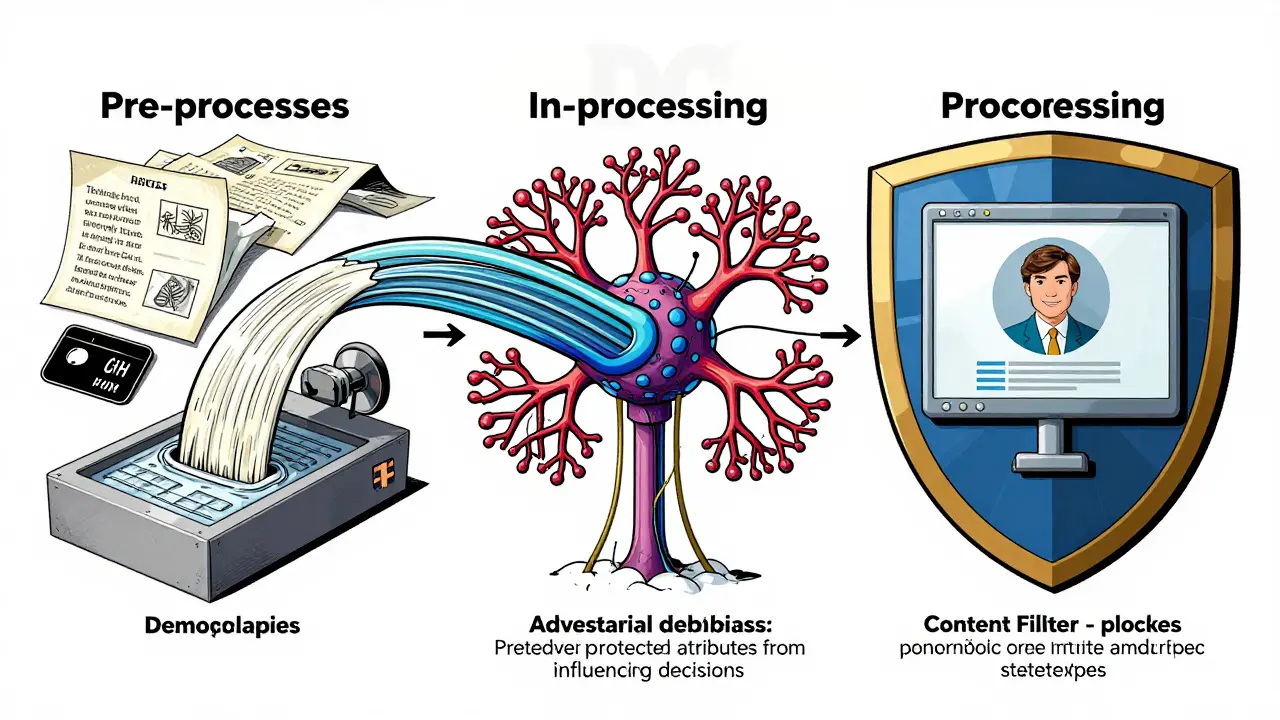
Finding bias is only half the battle. You need a structured plan to mitigate it. Remediation typically involves three stages: pre-processing, in-processing, and post-processing.
Pre-Processing: Data Curation
Bias often enters through the training data. If your dataset underrepresents Indigenous languages or overrepresents Western cultural norms, your model will reflect that imbalance. NVIDIA’s 2024 research showed a 29% improvement in minority group representation by using generative adversarial networks (GANs) specifically trained to balance dataset demographics. Audit your training data for representation gaps before you even start training.
In-Processing: Algorithmic Adjustments
During training, you can incorporate fairness constraints directly into the loss function. Techniques like adversarial debiasing train the model to predict labels while simultaneously preventing a secondary network from predicting protected attributes (like race or gender) from the hidden layers. This forces the model to learn features that are useful for the task but independent of protected characteristics.
Post-Processing: Output Filtering and Reweighting
If retraining isn’t feasible, you can adjust outputs after generation. This might involve:
- Threshold Adjustment: Setting different classification thresholds for different groups to equalize outcomes.
- Content Filters: Implementing real-time filters that detect and block stereotypical or harmful language before it reaches the user.
- Reweighting: Adjusting the probability distribution of generated tokens to favor more balanced associations.
Adobe’s Firefly image generator successfully reduced skin tone bias by 62% through fairness-aware training techniques verified by third-party auditors in Q4 2023. This demonstrates that technical remediation is possible and effective.
Regulatory Landscape and Compliance
The regulatory environment for AI fairness is evolving rapidly. Ignoring these requirements can lead to severe financial and reputational damage.
- EU AI Act: Requires "appropriate levels of accuracy, robustness, and cybersecurity" including fairness testing for high-risk AI systems. Non-compliance can result in fines up to 6% of global turnover.
- New York City Local Law 144: Effective January 2023, this law mandates annual bias audits for automated employment decision tools. Disparate impact ratios below 0.8 trigger legal scrutiny.
- U.S. State Legislation: As of 2024, 47 U.S. states have introduced AI fairness legislation, creating a patchwork of compliance requirements.
- White House OSTP Guidelines: Updated in November 2025, these guidelines require quarterly fairness audits for government-contracted AI systems.
For enterprises, compliance isn’t optional. Financial services (78% adoption) and healthcare (71% adoption) are leading the way due to high regulatory exposure. According to Lumenalta’s 2024 survey, enterprise adoption of formal fairness protocols surged from 22% in 2022 to 63% in 2024.
Best Practices for Implementation
Implementing a robust fairness testing framework takes time and expertise. Here’s how to get started:
- Integrate Early: Don’t wait until deployment. Stanford HAI’s 2025 report shows that 81% of leading AI labs now implement fairness considerations during data collection. Shift left in your development cycle.
- Document Everything: Adopt model cards, as recommended by Google and adopted by 68% of Fortune 500 companies. Document known limitations, such as underrepresentation of specific languages or cultural contexts.
- Build Cross-Functional Teams: Fairness isn’t just a data science problem. Include ethicists, legal experts, and community representatives in your review process. Dr. Alex Hanna of DAIR Institute notes that "fairness cannot be fully automated" and requires human interpretation.
- Monitor Continuously: Bias drifts over time as data changes. Implement continuous monitoring pipelines that track fairness metrics in production.
- Be Transparent: Share your findings with stakeholders. Transparency builds trust. Forrester’s 2025 analysis indicates that organizations with robust fairness frameworks see 19% higher customer satisfaction scores in diverse markets.
The journey toward fair generative AI is ongoing. As models become more powerful, so too must our methods for ensuring they serve everyone equitably. By adopting rigorous metrics, conducting thorough audits, and implementing thoughtful remediation plans, you can build AI systems that are not only intelligent but also just.
What is the difference between group fairness and individual fairness in generative AI?
Group fairness focuses on ensuring that outcomes are distributed equally across demographic segments (e.g., equal approval rates for loans). Individual fairness focuses on consistency, ensuring that similar individuals receive similar treatment regardless of their identity. In generative AI, group fairness might measure stereotype prevalence, while individual fairness checks if two similar prompts with different names yield similarly neutral responses.
How do I choose the right fairness metrics for my project?
Start by identifying the potential harms your AI could cause. If it allocates resources (like loans or jobs), use disparate impact and equalized odds. If it generates content (like text or images), focus on stereotype association scores and representation metrics. Always combine multiple metrics to get a complete picture, as no single metric captures all forms of bias.
Is fairness testing required by law?
In many jurisdictions, yes. The EU AI Act mandates fairness testing for high-risk AI systems. New York City’s Local Law 144 requires bias audits for employment tools. Additionally, 47 U.S. states have introduced relevant legislation. Even where not explicitly mandated, failing to conduct fairness testing exposes organizations to significant legal and reputational risks.
What tools are available for conducting AI fairness audits?
Several open-source and commercial tools are available. IBM’s AI Fairness 360 is a comprehensive toolkit for detecting and mitigating bias. Microsoft’s Fairlearn provides metrics and mitigation algorithms. For datasets, consider StereoSet and HolisticBias. Many organizations also use custom scripts built on top of TensorFlow or PyTorch to integrate fairness checks into their CI/CD pipelines.
Can fairness testing slow down my development cycle?
Yes, initially. A 2024 Kaggle survey found that 38% of developers reported increased development times when implementing comprehensive fairness testing. However, this upfront investment prevents costly post-deployment fixes, regulatory fines, and reputational damage. Integrating fairness early in the data collection phase helps minimize delays later in the process.


